Pipelines speedup
Often when you want to run some tests you need to install required dependencies such as python packages, ruby gems, npm packages and so on. Nowadays tests are executed automatically for pull (merge) requests in various CI systems. Dependency pulling is repeated again and again for every test run and it takes time. We cannot do much about it in cloud based CI systems such as Travis, Circle CI or Github Actions but there is some space for improvement for self-hosted Gitlab CI, Jenkins and others.
Cache
The first idea that would come to your mind is to enable cache. It looks reasonable. Why do need to redownload the same files again and again? Would it be better to store them in some near located storage? The answer is yes but there are some nuances. First of all we should decide how our cache mechanism will be implemented. I would highlight the following ways: caching proxy, cache in the same filesystem and the combination of these two methods.
Caching proxy
Using proxy makes sense if your organization consumes a significant amount traffic from package repositories. Having caching proxy reduces amount of incoming traffic and speeds up downloading. Besides local caching proxy can play a very important role in storing proprietary packages. There are several caching proxies and I worked with Sonatype Nexus and devpi.
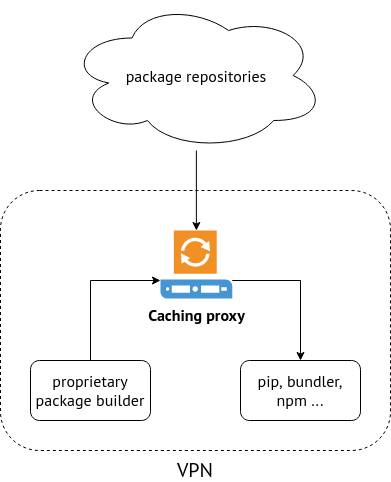
The most of the time I work with Python therefore below I will provide examples for its package
infrastructure. As you know Python standard package manager is pip and in order to download
packages from a caching proxy you have to specify an index url by one of the following methods:
pip.conf:
txt
[global]
index-url = https://example.com/pypi/packages
- environment variable:
PIP_INDEX_URL=https://example.com/pypi/packages - command line argument:
pip -i https://example.com/pypi/packages
Local cache
pip, gem, yum and others don't download packages from the index url immediately. Before that
they check if requested packages are stored locally in predefined directories of the file system.
Various package managers have different cache directories. pip in Linux stores downloads in
$HOME/.cache/pip by default. And again you can change that path via pip.conf, environment
variable PIP_CACHE_DIR or command line argument --cache-dir.
Cache in pipelines
That was a sort of preamble. Now we have a required knowledge in order to start a pipeline optimization. Let's designate prerequisites:
- you use Gitlab CI;
- Gitlab runner is configured to use kubernetes executor;
- a pipeline has a stage with installing python packages:
yaml
test:
image: python
stage: tests
before_script:
- pip install -U pip setuptools
- pip install -r requirements.txt
script:
- pytest
- there is a caching proxy that has the index url https://example.com/pypi/packages;
- you have a PVC with shared access.
First of all let's specify caching proxy index url in .gitlab-ci.yml:
test:
variables:
PIP_INDEX_URL: https://example.com/pypi/packages
Then we need to modify Gitlab runner config file in order to mount the PVC to builder pods:
[[runners]]
executor = "kubernetes"
# ...
cache_dir = "/mnt/cache"
[runners.kubernetes]
# ...
[runners.kubernetes.volumes]
# ...
[[runners.kubernetes.volumes.pvc]]
name = "name_of_pvc"
mount_path = "/mnt/cache"
It's a kind of an unobvious trick because according to the official documentation cache_dir setting is only for Shell, Docker and SSH executors.
And you supposed to use an S3 backend for storing cache. I found that trick in
Kubernetes cache support
issue.
And the final part is to modify the pipeline stage config:
test:
stage: tests
image: python
cache:
# that's the place where we tell Gitlab to treat that directory as a cache and
# properly handle the content of the directory
paths:
- .cache/pip
variables:
# Change pip's cache directory to be inside the project directory since we can
# only cache local items.
PIP_CACHE_DIR: $CI_PROJECT_DIR/.cache/pip
before_script:
- pip install -U pip setuptools
- pip install -r requirements.txt
script:
- pytest
Now in the pipeline log you should see something like that:
Restoring cache
Checking cache for default...
No URL provided, cache will not be downloaded from shared cache server. Instead a
local version of cache will be extracted.
Successfully extracted cache
Downloading artifacts
Running before_script and script
$ pip install -U pip setuptools
Collecting pip
# we don't download the package but use already downloaded from prior run
Using cached https://example.com/pypi/packages/pip-20.1.1-py2.py3-none-any.whl
...
Saving cache
Creating cache default...
.cache/pip: found 1505 matching files
No URL provided, cache will be not uploaded to shared cache server. Cache will be
stored only locally.
Created cache
In the end we should get the following package flow:
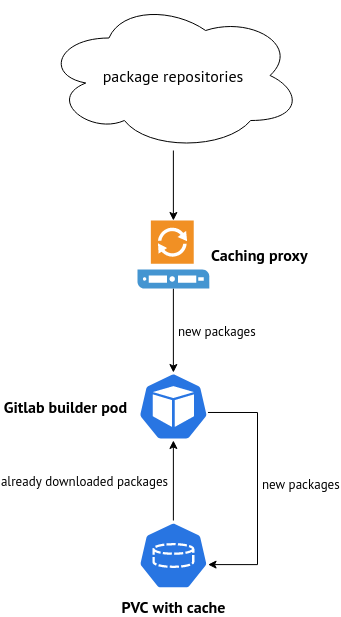
Enabling cache in some cases can speed up to several times pipeline execution. Because not only downloaded packages are cached but compiled as well.